

使用变量
核心概念
正如程序语言中的变量,在工作流中变量是用于串接和组织流程的重要工具。
在工作流触发后执行每个节点时,一些配置项可以选择使用变量,变量的来源即该节点的上游节点数据,包括以下几类:
- 触发上下文数据:操作触发、数据表触发等情况下,单行数据对象可以作为变量被所有节点使用,具体依据各个触发器实现各有不同。
- 上游节点数据:流程进行到任意节点时,之前已完成的节点的结果数据。
- 局域变量:当节点处在一些特殊分支结构内时,可以使用对应分支内特有的局域变量,例如循环结构中可以使用每轮循环的数据对象。
- 系统变量:一些内置的系统参数,如��当前时间等。
我们在 [快速开始] 中已经多次使用了变量的功能,例如在运算节点中,我们可以使用变量来引用触发上下文数据,来进行计算:
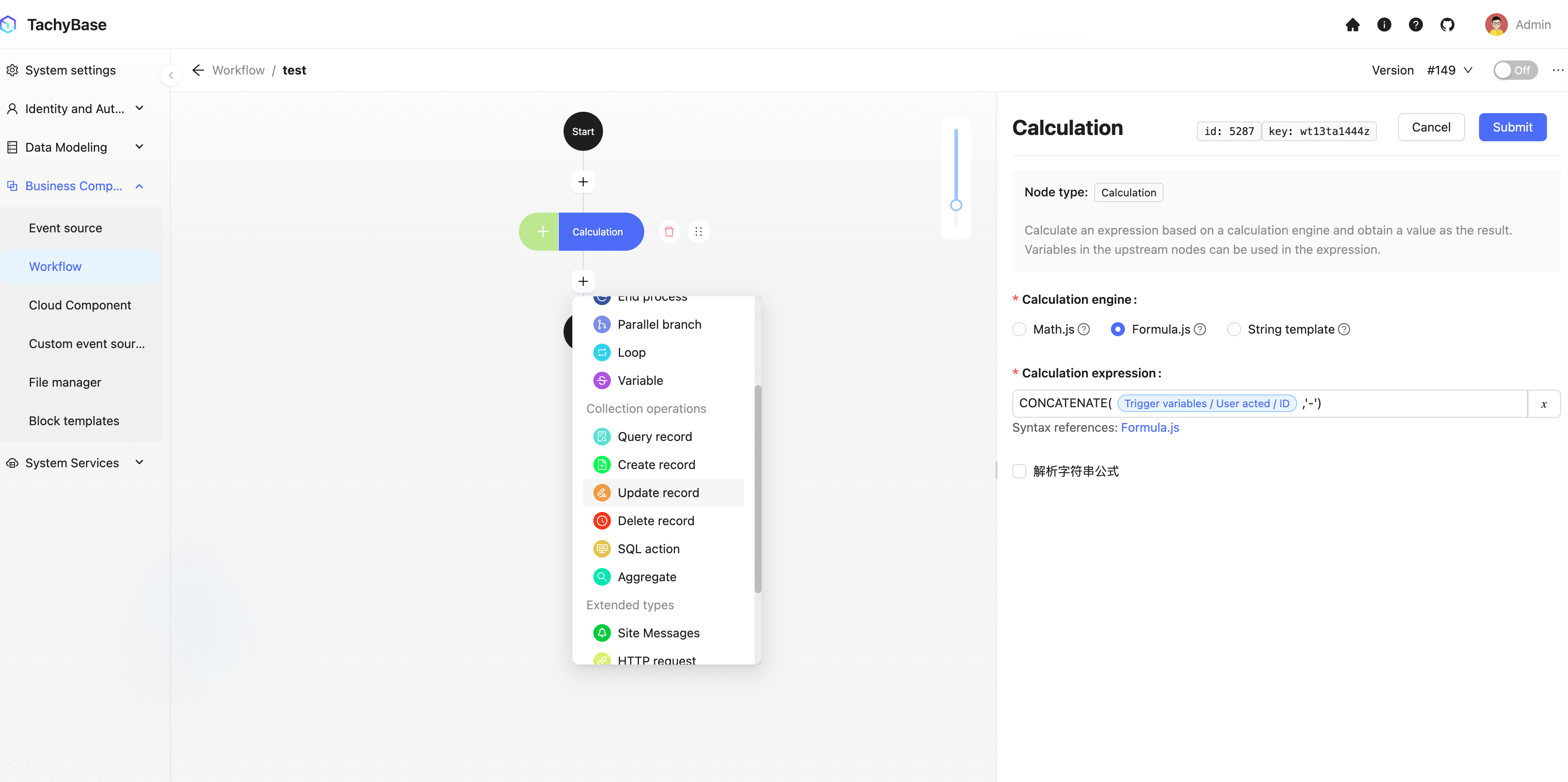
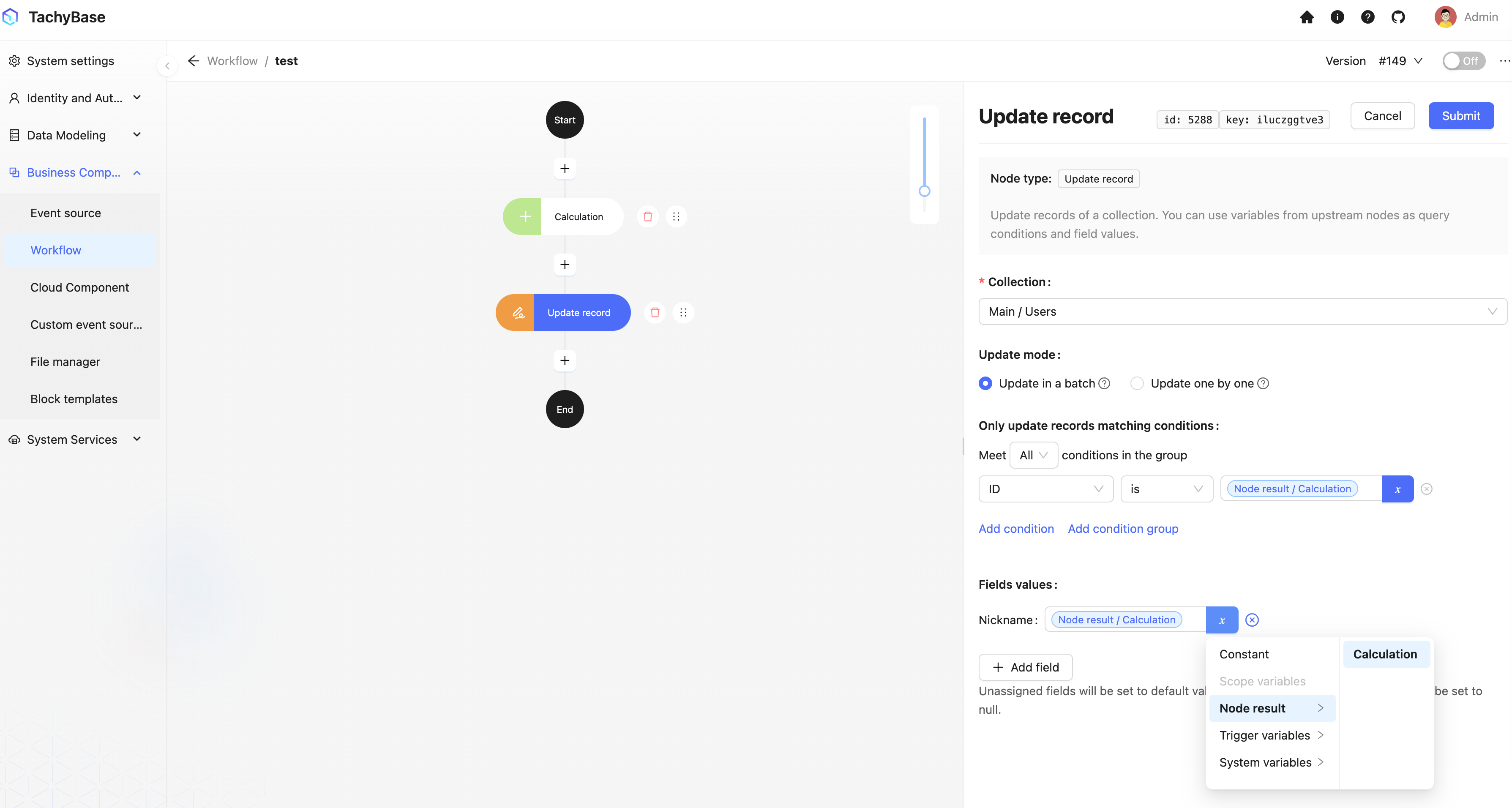
在更新节点中,使用触发上下文数据作为筛选条件的变量,并引用运算节点的结果作为更新数据的字段值变量:
数据结构
变量的内部是一个 JSON 结构,通常可以按 JSON 的路径使用数据的特定部分。由于很多变量基于 tachybase 的数据表结构,关系数据将会作为对象的属性按层级组成类似树的结构,例如我们可以选择查询到数据的关系数据的某个字段的值。另外当关系数据是对多的结构时,变量可能会是一个数组。
选择变量在大多数时候会需要选到最后一层值属性,通常是简单数据类型,如数字、字符串等。但当变量层级中有数组时,末级的属性也会被映射成一个数组,只有对应的节点支持数组的情况下,才能正确处理数组数据。例如在运算节点中,一些计算引擎有专门处理数组的函数,又比如在循环节点中,循环对象也可以直接选择一个数组。
举个例子,当一个查询节点查询了多条数据时,节点结果将会是一个包含多行同构数据的数组:
但是在后续节点中将其作为变量使用时,如果选择的变量是 节点数据/查询节点/标题 的形式,将会得到一个被映射后是对应字段值的数组:
如果是多维数组(如多对多关系字段),将会得到一个对应字段被拍平后的一维数组。
系统内置变量
系统时间
根据执行到的节点,获取执行当时的系统时间,该时间的时区是服务器设定的时区。
本站总访问量 次 本站访客数 人次 本文总阅读量 次. 由灵矶团队提供技术支持